01
第一步:写清主体和动作
Gemini Omni Flash prompt 的第一句定义谁/什么在画面中,以及在做什么。对外观要具体——不只是「一个女性」,而是「一位三十多岁、身穿白色亚麻衬衫的女性」。使用具体的动作动词:「走过」「举起」「转身面向镜头」。主体模糊会导致 Gemini Omni Flash 输出结果也模糊。
- 如果相关,包含年龄、服装、发色
- 使用具体动词,避免「是」或「站着」
Gemini Omni Flash 教程
Gemini Omni Flash 于 2026 年 5 月发布,是 Google 首款能在单次推理中同时生成同步视频和音频的模型。本教程涵盖所有内容:Gemini Omni Flash 是什么、它的 prompt 格式与其他模型有何不同,以及如何快速获得最佳效果。
Gemini Omni Flash 2026 年 5 月发布 · 可通过 Gemini 应用、Google Flow 和 YouTube Shorts 使用
理解 Gemini Omni Flash 底层的实际工作方式,是写出有效 prompt 的关键。
大多数 AI 视频模型只产出静音视频——你需要在后期另外添加音频。Gemini Omni Flash 不同:它在单次推理中同时生成同步的语音、音效和音乐。逐帧精准的 lip-sync 意味着角色嘴型与对话完全匹配,无需任何手动编辑。要触发这个功能,你的 Gemini Omni Flash prompt 必须包含音频指令——具体来说,是引号内的对话台词和音频环境描述。

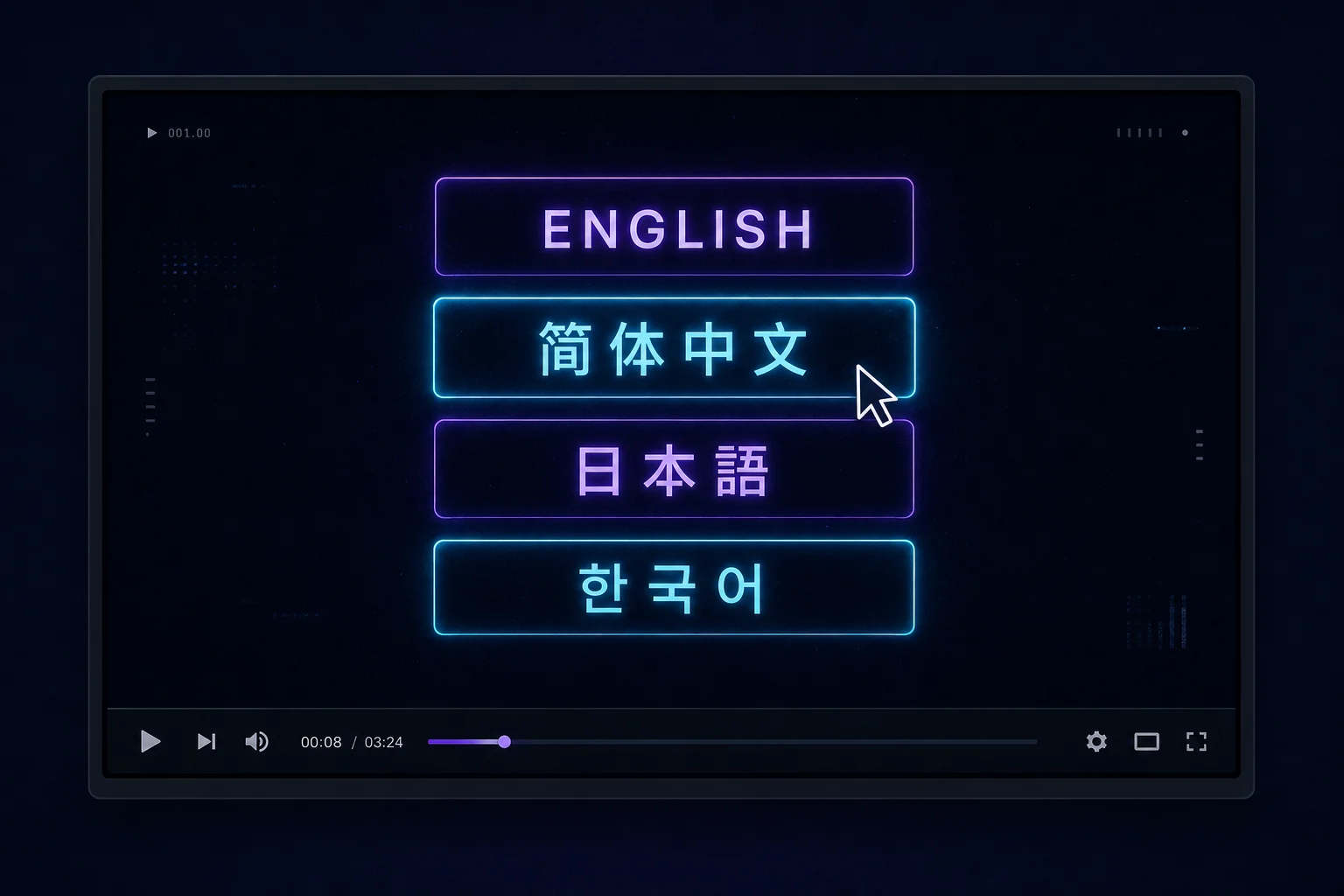
Gemini Omni Flash 的一项突出能力是能够在视频内部清晰渲染英文、中文、日文和韩文——不出现乱码、字符漂移或文字错位。大多数其他模型在内嵌文字上表现较差。在你的 Gemini Omni Flash prompt 中,明确写出屏幕上显示的文字内容和语言即可。例如:'在画面中央显示文字「春节快乐」(简体中文)3 秒钟。' 这对多语言产品广告和社交媒体内容尤为强大。
所有效果好的 Gemini Omni Flash prompt 都遵循同一套五段式结构。
Gemini Omni Flash prompt 的第一句定义谁/什么在画面中,以及在做什么。对外观要具体——不只是「一个女性」,而是「一位三十多岁、身穿白色亚麻衬衫的女性」。使用具体的动作动词:「走过」「举起」「转身面向镜头」。主体模糊会导致 Gemini Omni Flash 输出结果也模糊。
Gemini Omni Flash prompt 的第二句设置视觉参数。镜头景别(特写、全景、中景)、运镜(静态、推进、跟随)、环境(摄影棚、户外咖啡馆、霓虹灯街道)和视觉风格(电影感 35mm、平铺产品风、Vlog 风)都应在此写明。Gemini Omni Flash 有良好的物理理解能力——如果你写「微风轻动窗帘」,它会准确渲染。
这是大多数人跳过的步骤,却是 Gemini Omni Flash 最重要的一步。在第三句中加入:引号内的对话台词(用于 lip-sync)、音频环境描述(环境音),以及可选的音乐氛围。示例:'她说:「这款保湿霜改变了我的皮肤。」背景音频:轻柔的咖啡馆氛围,淡淡的爵士乐。' 没有这一步,Gemini Omni Flash 可能输出静音或音画不同步的内容。
制作产品广告时:以第一人称推荐语撰写对话。Gemini Omni Flash 渲染推荐语式 lip-sync 的效果特别好。
生成完整 Gemini Omni Flash PromptGemini Omni Flash 支持基于聊天的编辑——你可以修改特定元素而无需重新生成整个片段。输入「将背景改为日落时分的屋顶」或「把角色的衬衫改成蓝色」,Gemini Omni Flash 会保留未修改的部分。这与重新提示不同:它是针对性的增量编辑,能在多次修改中保持角色和场景的一致性。
这些是你的 prompt 能解锁的 Gemini Omni Flash 功能。写下一条 Gemini Omni Flash prompt 时可以作为参考。
Gemini Omni Flash 目前生成最长 10 秒的片段。如需更长内容,可拼接多段 Gemini Omni Flash 输出。Google 已宣布计划延长这一限制。
Gemini Omni Flash 在视频生成的同时联合生成语音、音效和音乐。只要在 prompt 中加入音频指令,无需单独的音频制作步骤。
Gemini Omni Flash 能在视频内部清晰渲染英文、简体中文、繁体中文、日文和韩文。在 prompt 中指定语言和文字内容即可。
通过自然语言对话修改 Gemini Omni Flash 片段中的特定元素。改动会保留场景中未修改的部分。
所有 Gemini Omni Flash 输出均包含 Google 的 SynthID 数字水印,用于验证 AI 生成内容。此功能自动添加,不影响画质。
Gemini Omni Flash 融合了 Gemini 对历史、科学和文化背景的知识。在 prompt 中引用真实世界背景(如「传统日本茶道」)能产出比通用描述更准确的结果。
这些场景下 Gemini Omni Flash 的表现优于其他 AI 视频模型——为每种场景选择正确的 Gemini Omni Flash prompt 模板。
Gemini Omni Flash 的 lip-sync 准确性使其非常适合第一人称产品推荐广告。写好对话台词,描述产品,让 Gemini Omni Flash 处理音视频同步。
Gemini Omni Flash 最佳使用场景使用 Gemini Omni Flash 在视频内部生成中文、日文或韩文字幕——这是 Seedance 2.0 和 Runway Gen-4.5 难以做到的。一条 Gemini Omni Flash prompt 就能产出完全本地化的片段。
多语言文字优势带同步配音的口播片段是 Gemini Omni Flash 的强项。使用音频指令模板:描述说话者,在引号内写好脚本,指定背景。
口播专项Gemini Omni Flash 的对话式编辑意味着你可以在不从头重新生成的情况下迭代片段。先生成一个基础 Gemini Omni Flash 片段,再逐个元素细化。
快速迭代关于 Gemini Omni Flash prompt、功能和使用权限的常见问题解答。
Gemini Omni Flash 是 Google 于 2026 年 5 月发布的多模态 AI 模型。它接受文本、图像、音频和视频作为输入,并在单次推理中生成带同步音频输出的视频——包括有 lip-sync 的对话、音效和音乐。可通过 Gemini 应用、Google Flow 和 YouTube Shorts 使用。
Gemini Omni Flash 可通过 Gemini 应用(gemini.google.com)、Google Flow(flow.google)和 YouTube Shorts 使用。2026 年 5 月发布后数周内开放了开发者 API 访问。需要 Google 账号——某些功能需要 AI Pro 或 AI Ultra 订阅。
Gemini Omni Flash 目前最长生成 10 秒的片段。Google 表示正在致力于延长这一限制。如需更长内容,可使用 Google Flow 的视频编辑工具将多个 10 秒 Gemini Omni Flash 片段拼接在一起。
静音输出通常意味着你的 prompt 缺少音频指令。只有当 prompt 明确包含音频提示时——引号内的对话台词、音频环境描述或音乐指令——Gemini Omni Flash 才会生成同步音频。在 prompt 中加入含这些元素的第三句话。
Gemini Omni Flash 在单镜头 lip-sync 音频、多语言文字渲染和对话式编辑方面表现突出。Seedance 2.0(字节跳动)在跨切多镜头序列、更长片段(最长 15 秒)和社交媒体画幅比例方面表现更佳。详见我们的完整对比页面。
支持。Gemini Omni Flash 能清晰渲染简体中文、繁体中文、日文和韩文的视频内部文字。在 prompt 中明确写出文字内容和语言即可:'在画面中央显示文字「你好世界」(简体中文)。'
Gemini Omni Flash 通过 Gemini 应用向所有 Google 账号持有者提供免费使用额度。某些高级功能和更高用量限制需要 AI Pro 或 AI Ultra 订阅。Google Flow 需要符合条件的 Google Workspace 或 AI Pro/Ultra 计划。
使用 OmniPrompt 的免费生成器,写出包含音频提示、镜头指令和平台优化格式的 Gemini Omni Flash prompt。
不到六十秒即可完成。
免费,浏览器端运行,无需注册。